上一节我们提到,使用openpyxl可以方便的对数据表进行操作,例如:
- 抽象Excel数据并存入数据库
- 将数据库数据导出到Excel
- 给一个已存在的数据表追加信息
我们还介绍了一些Excel的基本术语,在自己本地安装了openpyxl库并用库在本地创建了简单的Excel文件。 本节的主要内容是使用openpyxl来读取Excel表,你将掌握阅读数据表的方法,阅读从简单到复杂的各种例子,并将他们转化成Python内更有用的数据类型。让我们开始这一最重要的操作吧! 本节所涉及的数据集:
Dataset for openpyxl Tutorial – Real Python
本数据集来自亚马逊在线商品评论的真实数据,这只是Amazon商品的一小部分,但对于我们学习来说也足够了 请下载本数据集并存为“sample.xlsx” 简单阅读Excel表格的Python代码
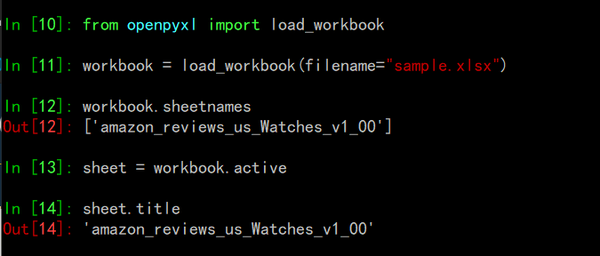
在上面的代码中:
- 首先用 load_workbook 方法打开了名为sample.xlsx的数据表,然后就可以使用workbook.sheetnames来查看所有你可用的sheet
- workbook.active 方法选择了第一个可用的sheet
- 使用该方法是默认的打开电子表的方法,在该教程中你会看到很多次
打开数据表之后,我们可以很容易的检索数据表:
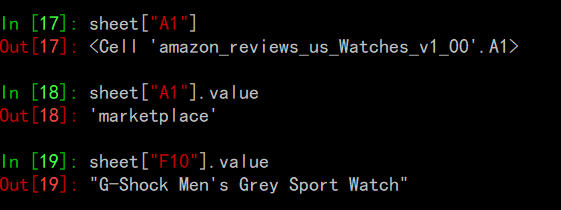
为了返回这个单元的具体数值,你需要使用.value,否则你得到的就会是这个对象。你也可以使用.cell() 通过指针符号检索数据,如下:
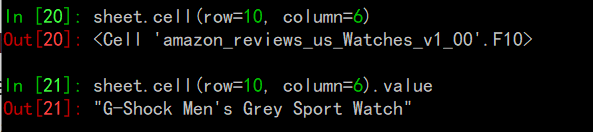
记住,要得到单元格的具体值而非单元格这个对象,就要使用.value来取值 你可以看到,不管你选用上述哪种方式定位单元格并取值,得到的结果相同。在本课程中,我们更多使用第一种:[“A1”]来定位单元格 注意,即使你在Python中使用 0 索引表示法,但在数据表中,你需要使用 1 索引法,(也就是说在Python中索引从0开始,但使用openpyxl时索引从1开始) 上述讨论了打开数据表最快的方法。然而,你可以通过传递其他参数来改变数据表的加载方式。加载方式如下所示。 其他的加载选项 在调用load_workbook() 时,你可以传递一些参数来改变数据表的加载方式。最重要的是如下两种:
- read_only:只读模式允许你打开非常大的Excel文件来加载数据表
- data_only:仅加载数据模式忽略加载公式,而只是加载结果数据
从数据表导入数据 现在你已经学习了加载数据表的基础,是时候进入有趣的环节了:迭代、在数据表中正式使用数值。在这部分,你将会学到所有你可能会用到的遍历数据方式,同时也会学到如何通过转换使得数据更加有用,当然,是以我们Pythonic方式啦。 遍历数据 根据不同的需求,有很多种不同的方法转换数据。你可以行列结合来切分数据:
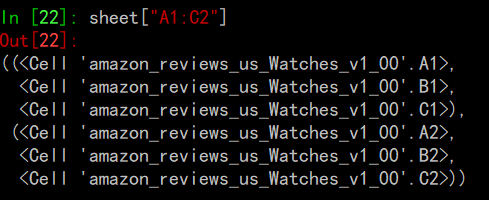
你可以得到行或列的范围:
图没有截全,包含了这张表所有A列的数据
仍然没截全,这次依次提取了A,B两列的数据,先A后B
返回第五行的数据
返回第五行和第六行的数据
你会注意到所有上述所有例子都返回 tuple,如果你想回忆Python如何操作list和tuple的话,请看这篇文章:
Lists and Tuples in Python – Real Python
还有多种使用Python生成器来浏览数据的方法,你能用于实现的主要有:
- .iter_rows()
- .iter_cols()
这两个方法都可以接收如下用于设置迭代的边界的参数:
- min_row
- max_row
- min_col
- max_col
示例如下:

按行打印
按列打印
你可能注意到了:在使用.iter_rows() 时,你每行得到一个选中的元组,而当你使用.iter_cols()时,你每列得到一个元组。 在上述的两个方法之中你都可以传递布尔值“values_only”,当该值被设置为True时,单元格的值而非单元格对象本身被返回:
只传回值
如果你想遍历整个数据集,那么你可以直接使用.rows,.columns等属性,这些属性是.iter_rows() 和.iter_cols() 无参数时的特例。
按行输出整个电子表
使用Python内部数据结构操作数据集: 现在你了解了遍历电子表格的数据的基础,让我们来看看如何将电子表的数据转换到Python的聪明方式吧! 正如你之前所看到的,通过迭代得到的结果都保存在元组中,然而,元组也不过是个不可变的列表,所以你可以轻松的获得元组数据并将它们转换为其他结构的数据。 例如,假设你想把sample.xlsx 中的数据抽象出产品信息并放进一个以产品id为key的dict,最直接的方法是遍历所有的行,挑选出你知道的与产品信息有关的列,然后将其存在字典里。让我们试试看! 第一步:查看表头,看看你最关心的有什么信息
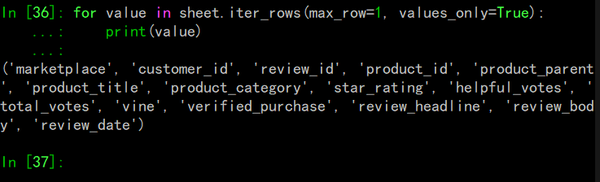
该代码返回了表格中所有的列名
首先,提取出如下列:
- product_id
- product_parent
- product_title
- product_category
很幸运的是,我们想要的数据都挨在一起,你可以使用min_col和max_col来很容易得到你想要的信息:
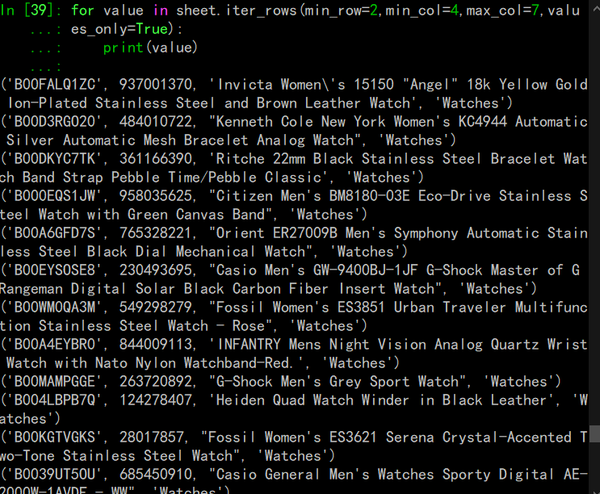
打印出想要的数据
非常好,你现在已经知道如何得到你需要的重要的产品信息了!现在我们把它放进字典中:
import json
from openpyxl import load_workbook
workbook = load_workbook(filename="sample.xlsx")
sheet = workbook.active
products = {}
# 使用values_only返回单元格的值
for row in sheet.iter_rows(min_row=2,
min_col=4,
max_col=7,
values_only=True):
product_id = row[0]
product = {
"parent": row[1],
"title": row[2],
"category": row[3]
}
products[product_id] = product
print(json.dumps(products))
这段代码将表格中除了第二行的每一行,4-7列的每一列打印出来,如图所示:
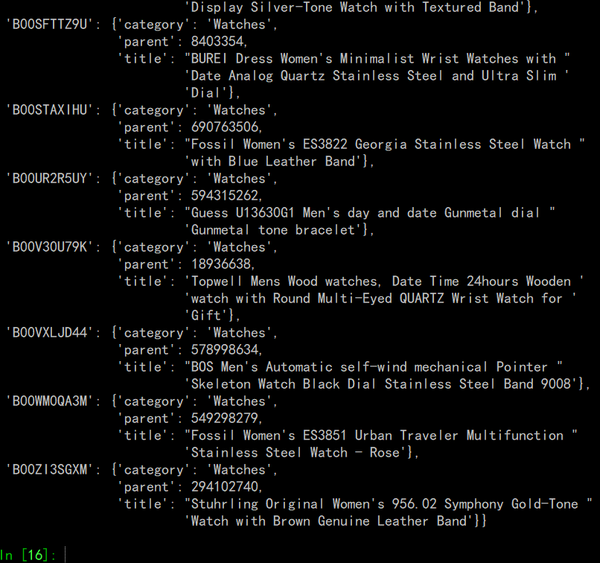
我在这里使用了pprint做整齐的字典打印, 一共98个
将数据转换到Python类中 为了完成本课程对Excel的读取部分,我们现在要深入到Python类中,看看你能在上面的案例的基础上如何提升并对数据进行更好的结构化。 关于数据类的教程我们将在其他专栏中专门介绍,为了完成上述目的,你应该使用从Python3.7开始支持的数据类。如果你使用老版本的Python,你可以使用默认的类来替代。 在一切开始之前,让我们看看你有什么数据,并且决定你想保存哪些,怎么保存吧。 正如你在开始看到的,这些数据来源于亚马逊的商品评论列表,你可以在如下链接查看这些数据的所有属性及其含义:
https://s3.amazonaws.com/amazon-reviews-pds/tsv/index.txts3.amazonaws.com
从数据中,有如下两个明显元素你可以从中提取:
- Product
- Reviews
每个产品有:
- ID
- Title
- Parent
- Category
评论有如下字段:
- ID
- Customer ID
- Stars
- Headline
- Body
- Date
import datetime
from dataclasses import dataclass
@dataclass
class Product:
id: str
parent: str
title: str
category: str
@dataclass
class Review:
id: str
customer_id: str
stars: int
headline: str
date: datetime.datetime
在定义你的数据类型之后,你需要将数据表中的数据转换到这些新的数据结构中。
在做这个转换之前,我们应该再次查看数据头,在列和字段之间创建映射关系:
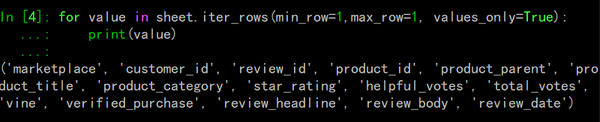
第一种遍历法
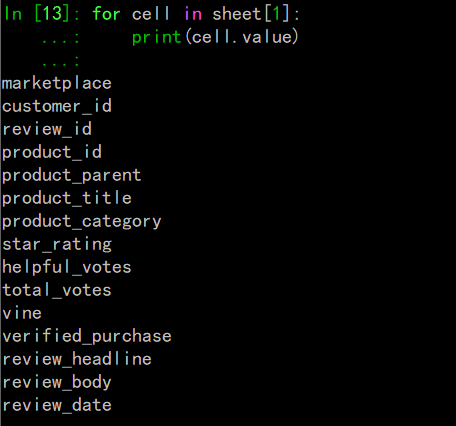
第二种遍历法
让我们创建一个文件mapping.py,在这个文件中包含所有字段名和他们的列的位置的列表。

你并不一定要执行上面的映射,但解析行数据时这样做更具有可读性,这样的话在执行结束后不会有一堆看起来奇怪的数字。
最后,让我们看看解析单元表数据到一个包含很多产品和评论的对象的列表需要哪些代码:
from datetime import datetime
from openpyxl import load_workbook
from classes import Product, Review
from mapping import PRODUCT_CATEGORY, PRODUCT_ID, PRODUCT_PARENT, PRODUCT_TITLE, \
REVIEW_DATE, REVIEW_STARS, REVIEW_ID, REVIEW_BODY, REVIEW_HEADLINE, REVIEW_CUSTOMER
# Using the read_only method since we are not gonna be editing the spreadsheet
workbook = load_workbook(filename="sample.xlsx", read_only=True)
sheet = workbook.active
products = []
reviews = []
# Using the values_only for we just want to return the cell value
for row in sheet.iter_rows(min_row=2, values_only=True):
product = Product(
id=row[PRODUCT_ID],
parent=row[PRODUCT_PARENT],
title=row[PRODUCT_TITLE],
category=row[PRODUCT_CATEGORY]
)
products.append(product)
# we need to parse the data from the spreadsheet into a datetime format
spread_date = row[REVIEW_DATE]
parsed_date = datetime.strptime(spread_date, "%Y-%m-%d")
review = Review(
id=row[REVIEW_ID],
customer_id=row[REVIEW_CUSTOMER],
stars=row[REVIEW_STARS],
headline=row[REVIEW_BODY],
date=parsed_date
)
reviews.append(review)
print(products[0])
print(reviews[0])
运行该代码后,得到如下输出:

这就对了! 现在你得到了如此简单易懂的类形式的数据,你可以开始考虑将他们存在数据库里,或者任何别的类型的形式了!
使用这种面向对象的策略来解析数据表使得以后处理数据如此简单!