百度飞桨 PaddleOCR 初体验(一) 日语
最近项目原因接触到PaddleOCR,由于本人对于深度学习领域一窍不通,希望写一个专栏,从初学者的角度一点点学习PaddleOCR
首先是部署,我没有选择docker部署,而是直接:
pip3 install --upgrade pip
然后:git clone https://github.com/PaddlePaddle/PaddleOCR
第三方库再拉满:
cd PaddleOCR
pip3 install -r requirements.txt
接下来下载inference模型:
mkdir inference && cd inference
wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_infer.tar && tar xf ch_ppocr_mobile_v2.0_det_infer.tar
wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_infer.tar && tar xf ch_ppocr_mobile_v2.0_rec_infer.tar
wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar && tar xf ch_ppocr_mobile_v2.0_cls_infer.tar
cd ..
这里的链接是超轻量级中文模型,我使用的是中英文通用模型。
配置到这里,就可以开始愉快的使用了。
# 预测image_dir指定的单张图像
python3 tools/infer/predict_system.py --image_dir="./doc/imgs/11.jpg" --det_model_dir="./inference/ch_ppocr_mobile_v2.0_det_infer/" --rec_model_dir="./inference/ch_ppocr_mobile_v2.0_rec_infer/" --cls_model_dir="./inference/ch_ppocr_mobile_v2.0_cls_infer/" --use_angle_cls=True --use_space_char=True
# 预测image_dir指定的图像集合
python3 tools/infer/predict_system.py --image_dir="./doc/imgs/" --det_model_dir="./inference/ch_ppocr_mobile_v2.0_det_infer/" --rec_model_dir="./inference/ch_ppocr_mobile_v2.0_rec_infer/" --cls_model_dir="./inference/ch_ppocr_mobile_v2.0_cls_infer/" --use_angle_cls=True --use_space_char=True
# 如果想使用CPU进行预测,需设置use_gpu参数为False
python3 tools/infer/predict_system.py --image_dir="./doc/imgs/11.jpg" --det_model_dir="./inference/ch_ppocr_mobile_v2.0_det_infer/" --rec_model_dir="./inference/ch_ppocr_mobile_v2.0_rec_infer/" --cls_model_dir="./inference/ch_ppocr_mobile_v2.0_cls_infer/" --use_angle_cls=True --use_space_char=True --use_gpu=False
这里是超轻量级模型的使用方法。
以上内容其实官网上都能找到,但我需要的是日语模型,所以需要找到官方模型并进行修改
文本方向分类模型、文本监测模型 可以多语言通用,但是文本识别模型则需要通过重新下载并且配置。
但是配置进来后,生成的并不是我想要的,而是一堆中文乱码。
调研后,发现是字体字典路径&字体类型没有使用日文,使用日文后就可以了。
命令如下:
python3 tools/infer/predict_system.py --image_dir="./doc/imgs/japan_1.jpg" --det_model_dir="./inference/ch_ppocr_server_v2.0_det_infer/" --rec_model_dir="./inference/japan_mobile_v2.0_rec_infer/" --use_gpu=False --rec_char_type="japan" --rec_char_dict_path="./ppocr/utils/dict/japan_dict.txt"
效果如下:
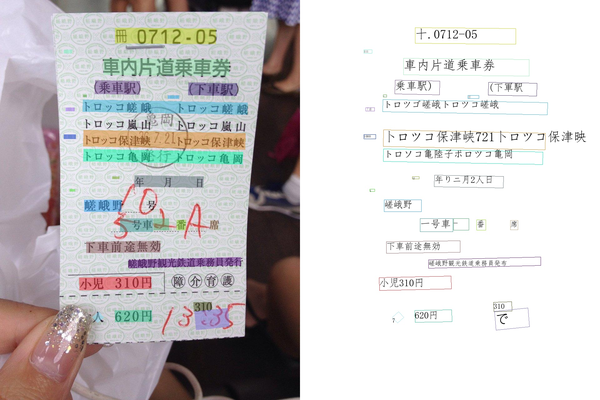
能看出来效果还可以,但是很多情况下置信度并不高,而且多次检测下来,发现字体文件好像不全。慢慢研究。